
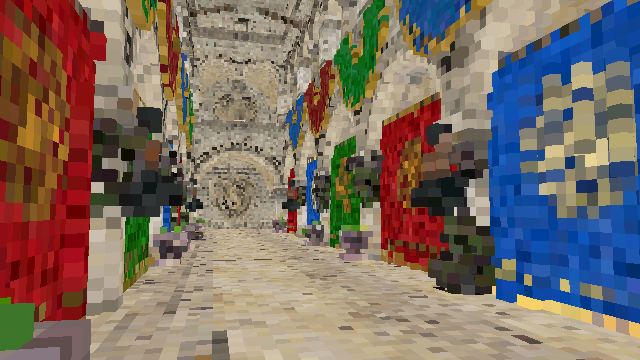

Voxelization
My focus has been on the process of voxelization, implemented through a compute shader running per triangle. The triangles dominant axis is calculated; and then the three points are sorted from lowest to highest in the dominant axis. The three edges are voxelized using a algorithm based on A Fast Voxel Traversal Algorithm for Ray Tracing.
The flexibility of compute shaders makes it seamless to consider transitioning to a sparse voxel octree in the future, or other memory efficent storage method.
The center of the triangle is then voxelized with the help of scanlines and the same voxel traversal algorithm used for the edges.
fn voxelize_interior(triangle: Triangle) {
let next_plane = floor(triangle.vertices[0].grid_position[triangle.dom_axis] + 1.0);
let max_plane = triangle.vertices[2].grid_position[triangle.dom_axis] - 0.5;
var plane = next_plane + 0.5;
let dir01 = triangle.vertices[0].grid_position - triangle.vertices[1].grid_position;
let dir02 = triangle.vertices[0].grid_position - triangle.vertices[2].grid_position;
let dir12 = triangle.vertices[1].grid_position - triangle.vertices[2].grid_position;
let dom_length_01 = triangle.vertices[1].grid_position[triangle.dom_axis] - triangle.vertices[0].grid_position[triangle.dom_axis];
let dom_length_02 = triangle.vertices[2].grid_position[triangle.dom_axis] - triangle.vertices[0].grid_position[triangle.dom_axis];
let dom_length_12 = triangle.vertices[2].grid_position[triangle.dom_axis] - triangle.vertices[1].grid_position[triangle.dom_axis];
while plane < max_plane {
let t_02 = (plane - triangle.vertices[0].grid_position[triangle.dom_axis]) / dom_length_02;
let p_02 = triangle.vertices[0].grid_position - (t_02 * dir02);
var end: vec3<f32>;
if triangle.vertices[1].grid_position[triangle.dom_axis] >= plane {
let t_01 = (plane - triangle.vertices[0].grid_position[triangle.dom_axis]) / dom_length_01;
let p_01 = triangle.vertices[0].grid_position - (t_01 * dir01);
end = p_01;
} else {
let t_12 = (plane - triangle.vertices[1].grid_position[triangle.dom_axis]) / dom_length_12;
let p_12 = triangle.vertices[1].grid_position - (t_12 * dir12);
end = p_12;
}
voxelize_line(triangle, p_02, end);
plane += 1.0;
}
}
Voxel Debug Rendering
While the debug rendering may be considered naive, it serves its purpose effectively. Through a two-pass system of compute shaders, the first pass counts the voxels in the 3D texture, and the second generates the indices and vertices used for rendering. Despite occasional challenges, like max buffer size errors, it has done it’s job in providing a visual confirmation of the voxelization.
Code Cleanup
Moving forward, my focus is on code cleanup. Despite concerns about code quality when starting the project, I temporarily shifted my attention to voxelization to have a visual element for this portfolio. Now, I’m excited to streamline the codebase by introducing traits and macros for minification of boilerplate. This strategy, coupled with leveraging the Rust type system for different types of , is a work in progress but already showing promising results, as demonstrated by the sample code provided next.
from:
use wgpu::util::DeviceExt;
use wgpu::BufferAsyncError;
#[test]
fn new_buffer() {
let instance = wgpu::Instance::default();
let adapter =
pollster::block_on(instance.request_adapter(&wgpu::RequestAdapterOptions::default()))
.unwrap();
let (device, queue) = pollster::block_on(adapter.request_device(
&wgpu::DeviceDescriptor {
label: None,
features: wgpu::Features::empty(),
limits: wgpu::Limits::default(),
},
None,
))
.unwrap();
let cs_module = device.create_shader_module(wgpu::ShaderModuleDescriptor {
label: None,
source: wgpu::ShaderSource::Wgsl(std::borrow::Cow::Borrowed(include_str!(
"bind_group.wgsl"
))),
});
let staging_buffer = device.create_buffer(&wgpu::BufferDescriptor {
label: Some("Test Staging Buffer"),
size: std::mem::size_of::<[[f32; 4]; 4]>() as u64,
usage: wgpu::BufferUsages::MAP_READ | wgpu::BufferUsages::COPY_DST,
mapped_at_creation: false,
});
let orig_data= [[1.5_f32; 4]; 4];
let test_buffer = device.create_buffer_init(&wgpu::util::BufferInitDescriptor {
label: Some("Test Data Buffer"),
contents: bytemuck::cast_slice(&orig_data),
usage: wgpu::BufferUsages::STORAGE | wgpu::BufferUsages::COPY_DST | wgpu::BufferUsages::COPY_SRC,
});
let bind_group_layout = device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor {
label: Some("Test Bind Group Layout"),
entries: &[wgpu::BindGroupLayoutEntry {
binding: 0,
visibility: wgpu::ShaderStages::COMPUTE,
ty: wgpu::BindingType::Buffer {
ty: wgpu::BufferBindingType::Storage { read_only: false },
has_dynamic_offset: false,
min_binding_size: None,
},
count: None,
}],
});
let bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
label: Some("Test Bind Group"),
layout: &bind_group_layout,
entries: &[wgpu::BindGroupEntry {
binding: 0,
resource: test_buffer.as_entire_binding(),
}],
});
let compute_pipeline_layout = device.create_pipeline_layout(&wgpu::PipelineLayoutDescriptor {
label: Some("Test Pipeline"),
bind_group_layouts: &[&bind_group_layout],
push_constant_ranges: &[],
});
let compute_pipeline = device.create_compute_pipeline(&wgpu::ComputePipelineDescriptor {
label: None,
layout: Some(&compute_pipeline_layout),
module: &cs_module,
entry_point: "main",
});
let mut encoder =
device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None });
{
let mut cpass = encoder.begin_compute_pass(&wgpu::ComputePassDescriptor {
label: None,
timestamp_writes: None,
});
cpass.set_pipeline(&compute_pipeline);
cpass.set_bind_group(0, &bind_group, &[]);
cpass.insert_debug_marker("compute collatz iterations");
cpass.dispatch_workgroups(1, 1, 1); // Number of cells to run, the (x,y,z) size of item being processed
}
encoder.copy_buffer_to_buffer(&test_buffer, 0, &staging_buffer, 0, test_buffer.size());
queue.submit(Some(encoder.finish()));
let (tx, rx) = std::sync::mpsc::channel::<Result<(), BufferAsyncError>>();
let staging_slice = staging_buffer.slice(..);
staging_slice.map_async(wgpu::MapMode::Read, move |res| {
tx.send(res).unwrap();
});
loop {
device.poll(wgpu::MaintainBase::Wait);
match rx.recv() {
Ok(_) => {
let buffer_view = staging_slice.get_mapped_range();
let data: &[[f32; 4]; 4] = unsafe { &*(buffer_view.as_ptr() as *const [[f32; 4]; 4]) };
assert_eq!(data, &[[3.0_f32; 4]; 4]);
break;
}
Err(e) => {
panic!("{:?}", e);
}
}
}
}
to:
use ::wgpu_helper::*;
use wgpu_helper::bind_group::*;
const TEST_BIND_GROUP_LAYOUT: &'static wgpu::BindGroupLayoutDescriptor<'static> =
&wgpu::BindGroupLayoutDescriptor {
label: Some("Test Bind Group"),
entries: &[wgpu::BindGroupLayoutEntry {
binding: 0,
visibility: wgpu::ShaderStages::COMPUTE,
ty: wgpu::BindingType::Buffer {
ty: wgpu::BufferBindingType::Storage { read_only: false },
has_dynamic_offset: false,
min_binding_size: None,
},
count: None,
}],
};
#[derive(BindGroup)]
#[layout(TEST_BIND_GROUP_LAYOUT)]
pub struct TestBindGroup<'a> {
pub indices: &'a crate::Buffer<crate::types::mat4x4f>,
}
#[test]
fn new_buffer() {
let instance = wgpu::Instance::default();
let adapter =
pollster::block_on(instance.request_adapter(&wgpu::RequestAdapterOptions::default()))
.unwrap();
let (device, queue) = pollster::block_on(adapter.request_device(
&wgpu::DeviceDescriptor {
label: None,
features: wgpu::Features::empty(),
limits: wgpu::Limits::default(),
},
None,
))
.unwrap();
let cs_module = device.create_shader_module(wgpu::ShaderModuleDescriptor {
label: None,
source: wgpu::ShaderSource::Wgsl(std::borrow::Cow::Borrowed(include_str!(
"bind_group.wgsl"
))),
});
let staging_buffer = wgpu_helper::Buffer::<crate::types::mat4x4f>::new(
&device,
wgpu::BufferUsages::MAP_READ | wgpu::BufferUsages::COPY_DST,
false,
);
let orig_data: crate::types::mat4x4f = [[1.5_f32; 4]; 4].into();
let storage_buffer = wgpu_helper::Buffer::new_init(
&device,
&orig_data,
wgpu::BufferUsages::STORAGE | wgpu::BufferUsages::COPY_DST | wgpu::BufferUsages::COPY_SRC,
);
let bind_group = TestBindGroup {
indices: &storage_buffer,
};
let official_bind_group = bind_group.to_bind_group(&device, None);
let bind_group_layout = TestBindGroup::get_bind_group_layout(&device);
let compute_pipeline_layout = device.create_pipeline_layout(&wgpu::PipelineLayoutDescriptor {
label: Some("Test Pipeline"),
bind_group_layouts: &[bind_group_layout],
push_constant_ranges: &[],
});
let compute_pipeline = device.create_compute_pipeline(&wgpu::ComputePipelineDescriptor {
label: None,
layout: Some(&compute_pipeline_layout),
module: &cs_module,
entry_point: "main",
});
let mut encoder =
device.create_command_encoder(&wgpu::CommandEncoderDescriptor { label: None });
{
let mut cpass = encoder.begin_compute_pass(&wgpu::ComputePassDescriptor {
label: None,
timestamp_writes: None,
});
cpass.set_pipeline(&compute_pipeline);
cpass.set_bind_group(0, unsafe { official_bind_group.as_untyped() }, &[]);
cpass.insert_debug_marker("compute collatz iterations");
cpass.dispatch_workgroups(1, 1, 1); // Number of cells to run, the (x,y,z) size of item being processed
}
storage_buffer.copy_to_buffer(&mut encoder, &staging_buffer);
queue.submit(Some(encoder.finish()));
assert_eq!(staging_buffer.map_sync(&device), &[[3.0_f32; 4]; 4].into());
}